Analyzing my sleep and diet in R
For years, I’ve tracked my daily levels of sleep and other variables about my life in a big spreadsheet. While trying to analyze the data, I ran into some tricky R issues that I managed to beat, so I’m publishing my source code in case that helps you too.
To try this example, you’ll the the tidyverse collection of R packages and a dataframe like mine, which I call rikStats, with my daily statistics. The columns are the different variables I track, and each row is a unique single day. You can read this directly from the Excel file where I created it, or through some other means. The data frame looks kind of like this, minimally with the variables Date and Z (for the amount of sleep that day) along with any other variables you like, such as Coffee, which is the number of cups I had that day.
## # A tibble: 732 x 3
## Z Date Coffee
## <dbl> <date> <dbl>
## 1 9 2017-01-01 NA
## 2 6 2017-01-02 1
## 3 6 2017-01-03 2
## 4 6.5 2017-01-04 3
## 5 7 2017-01-05 3
## 6 6 2017-01-06 2
## 7 6 2017-01-07 2
## 8 6.5 2017-01-08 1
## 9 5 2017-01-09 2
## 10 6 2017-01-10 2
## # … with 722 more rowsI recently experimented with a a low carbohydrate high fat (LCHF) diet for three months. How did that affect my sleep? I’d like to compare my sleep times during the LCHF diet to the days when I was on my regular, anything-goes diet.
Calculating this in R is trickier than it appears. Of course it’s super-easy to simply chart Z for each day, but my sleep times per day are highly variable and it’s hard to see clear patterns on a daily basis. Instead, I’d like to plot the mean daily values per week or month. When the averages are spread over a longer time period, I hope to see more patterns.
How do you tell R to look at just the averages per week? Because my data spans multiple years, it’s not enough to simply plot the week number – somehow I must keep track of a combination of the year and the week. I tried several different approaches, including building a whole new dataframe that had the correct week numbers spread across years, but then I couldn’t easily plot it on a time axis. If any of my daily data points were missing, a plot that doesn’t understand dates will be unable to correctly show time lapse for missing values.
Fortunately, R includes a powerful cut() function to slice data however I like; in this case, weeklong segements of the Date vector. cut() also lets me change the duration if I want to try averages that are biweekly, quarterly, or pretty much any other time span.
The following code groups the data by week and creates a new dataframe df with a column MeanZ that contains the mean values per week.
lchf.dates <- seq(lubridate::ymd("2017-12-01"),lubridate::ymd("2018-02-28"),by=1)
# get rid of that first day in January, which is an outlier
df <- rikStats[-1,] %>% dplyr::filter(Date < "2018-03-01" & Z>5) %>%
group_by(Week = cut(Date, "1 week")) %>%
mutate(MeanZ = mean(Z)) %>% select(Week, Date,MeanZ)
ggplot(df,aes(x=Date,y=MeanZ)) + geom_line(stat="identity") +
ggtitle("Sleep Times (Weekly Average)") +
geom_rect(data=data.frame(xmin=5000, xmax=10000, ymin=-Inf, ymax=Inf),
aes(xmin=lchf.dates[1], xmax=tail(lchf.dates,1), ymin=-Inf, ymax=Inf),
fill="red",
alpha=0.2,
inherit.aes = FALSE) +
geom_smooth(method = "loess") +
annotate("text",x=lchf.dates[1]+length(lchf.dates)/2,y=7.5,label = "LCHF Diet") +
theme(axis.text.x = element_text(angle=90))## `geom_smooth()` using formula 'y ~ x'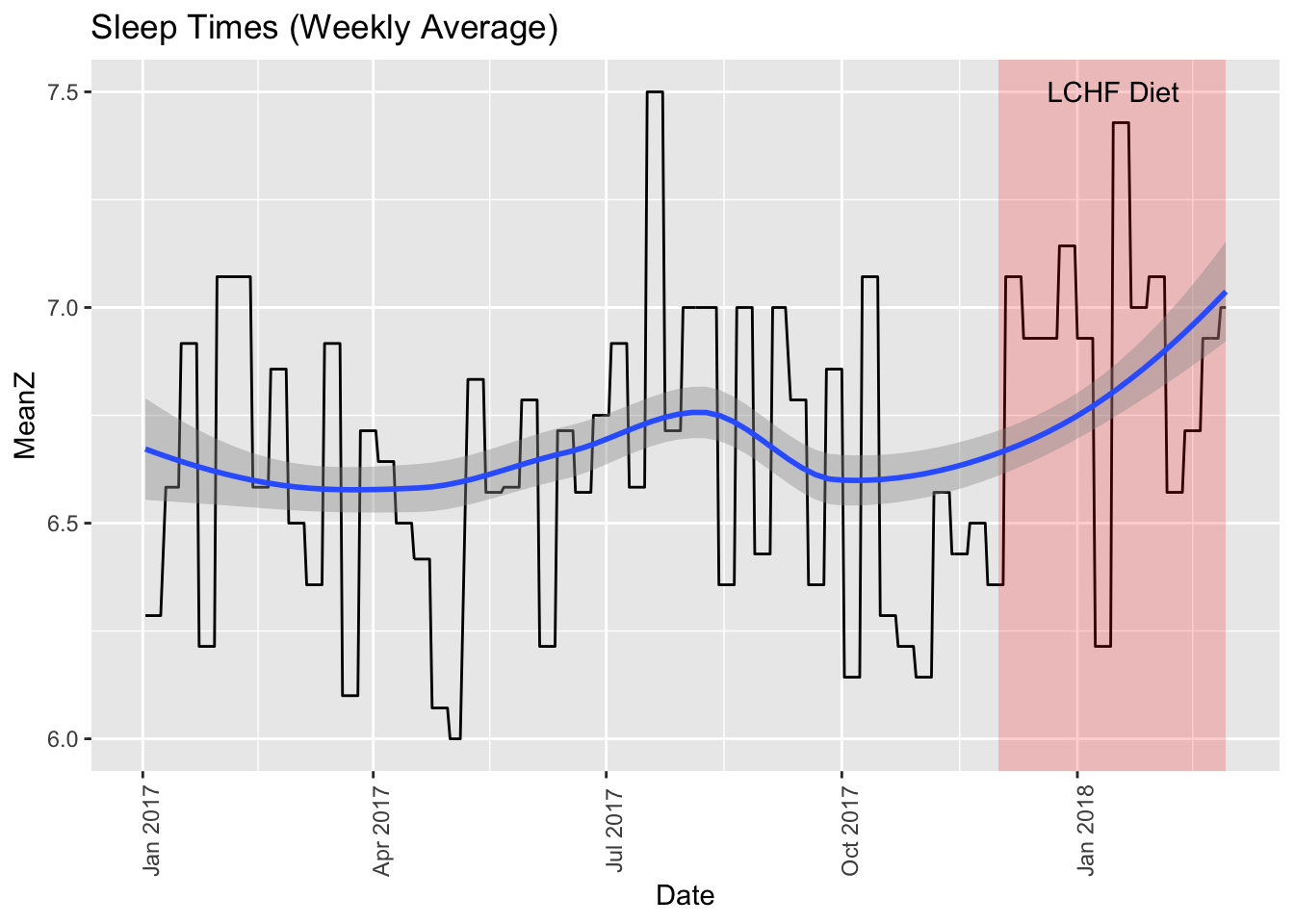 To round out the example, note that I highlighted the part of the graph that represents the LCHF days. I also added a “loess” curve that shows the moving average of my sleep across time.
To round out the example, note that I highlighted the part of the graph that represents the LCHF days. I also added a “loess” curve that shows the moving average of my sleep across time.
Finally, for a quick and dirty look at some statistics, let’s apply a simple T-Test, comparing all the Z values for the Regular diet with those for the LCHF diet.
rikStats$Diet <- "Regular"
rikStats$Diet[!is.na(match(rikStats$Date,lchf.dates))] <- "LCHF"
t.test(dplyr::filter(rikStats,Diet=="Regular")$Z,
dplyr::filter(rikStats,Diet=="LCHF")$Z,
conf.level = 0.9999)##
## Welch Two Sample t-test
##
## data: dplyr::filter(rikStats, Diet == "Regular")$Z and dplyr::filter(rikStats, Diet == "LCHF")$Z
## t = -5.7916, df = 206.08, p-value = 2.577e-08
## alternative hypothesis: true difference in means is not equal to 0
## 99.99 percent confidence interval:
## -0.8907859 -0.1664312
## sample estimates:
## mean of x mean of y
## 6.376947 6.905556Simply put, this says that we can say with high confidence that the mean amount of sleep I got on LCHF days was higher than the mean on regular days. To do a full-blown analysis, we’d need to look more closely at the trends in the data and account for the fact that the various sleep days aren’t completely independent of each other. But at a first glance, it looks awfully like we have a real effect.